国产情色 英伟达GeForce 6000系列里面

 国产情色
国产情色
本文由半导体产业纵横(ID:ICVIEWS)编译自Chips and Cheese
是时候来聊聊英伟达GeForce 6系列显卡了。
2025 年发轫,显卡鸿沟就搅扰不凡。英特尔的 Arc B580 标明,制造一款显存(VRAM)高出 8GB 的中端显卡仍是可行的。AMD 的 RDNA 4 连续了 AMD 长期以来的一种作念法,即在追求高端居品之后,又认为终究不太值得。英伟达在 2025 年也推出了新一代居品,他们的 5000 系列显卡也曾发布,但市面上却一直莫得现货。不外,数字越大越好,是以面前是时候来聊聊英伟达 GeForce 6 系列显卡了。

每一代游戏玩家都对更高质料的图形成果有所需求。莫得东谈主比英伟达更廓清这极少,因此英伟达 GeForce 6000 系列显卡旨在以富裕高的帧率提供接近电影级的画质,以扶助交互式游戏体验。GeForce 6000 显卡,简称 GeForce 6 系列,在谋略时计划到了图形渲染的高度并行性。与此同期,它们在可编程性方面达成了普遍飞跃,为达成复杂的游戏内殊效开辟了令东谈主郁勃的新可能。
综合
图形渲染触及在测度最终像素面貌之前,将偏激坐标从三维空间编削到二维屏幕空间,这一流程被称为光栅化。这两个阶段本体上都是并行任务,而况能很好地适配领有无数奉行单位阵列的硬件。因此,英伟达GeForce 6 系列是一种大限制并行处理果然立。它领有无数的固定功能图形硬件,但该显卡的简直实力在于其一系列偏激着色器中枢和像素着色器中枢。这些可编程组件奉行由游戏提供的着色器身手,而不是奉行预设功能。它们还充任基本的构建模块,使英伟达简略针对不同的功耗、价钱和性能决策进行推广。英伟达 GeForce 6000 系列中最高端的芯片 NV40 配备了 6 个偏激着色器中枢和 16 个像素着色器中枢。
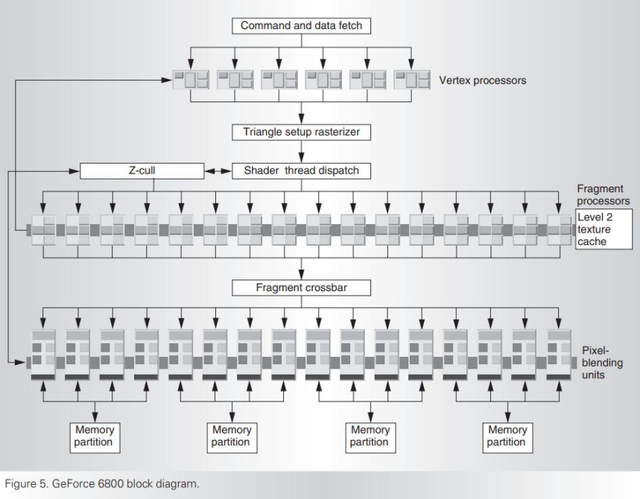
摘自英伟达发表于电气与电子工程师协会(IEEE)的论文
一台高度并行的机器需要一个高带宽的内存子系统来为其提供数据扶助。英伟达 GeForce 6 系列居品最高可配备 256 位的 GDDR3 动态立时存取存储器,这使得它的内存总线宽度比典型的台式机中央处理器要宽得多。该显卡具有一个可被整个像素着色器中枢和偏激着色器中枢分享的二级纹理缓存,这使得获得到的纹理数据简略在短期内被重迭使用。英伟达其时并未露出缓存的大小,但他们的决策是在有很多未射中情况同期发生时达到 90% 的射中率,而不是像中央处理器缓存那样经常追求 99% 的射中率。该显卡通过流行的加快图形接口(AGP)与主机系统进行通讯,但也能扶助行将推出的外设部件互连高速圭表。
偏激着色器中枢(Vertex Shader Core)
偏激着色器身手将坐标从三维空间编削到二维屏幕空间。这听起来可能是一项粗浅的任务,无非等于进行相机矩阵乘法和透视除法运算。但可编程的偏激着色器带来了新的手段。举例,一个偏激着色器不错对纹理进行采样,并将其用作置换贴图。除了扶助纹理造访除外,英伟达 GeForce 6000 的偏激着色器中枢还扶助分支、轮回和函数调用。在简直的中央处理器除外,夙昔在其他确立上,这些功能中的大部分都是难以思象的,这展示了显卡发展的令东谈主郁勃之处。
偏激着色器的奉行从一个领有 512 个条见识提醒立时存取存储器中索求提醒驱动。英伟达使用来自驱上路手姿色的 128 位偏激提醒,这些提醒会被编削为 123 位的里面姿色。因此,该提醒立时存取存储器的容量轻便为 8 千字节。DirectX 9 的偏激着色器 3.0 圭表国法至少要有 512 个提醒插槽,而况英伟达的偏激着色器中枢提醒集架构与 DirectX 9 的高等着色器说话提醒详细契合。由于存在提醒收尾,着色器身手不会像中央处理器身手那样经常因提醒缓存未射中而导致性能赔本。此外,造访提醒立时存取存储器不像缓存那样需要进行标签比较,从而纯粹了功耗。

从梅萨(Mesa)代码中推断出的英伟达 GeForce 6000 偏激着色器提醒布局
DirectX 9偏激着色器的高等着色器说话提醒大致可分为标量提醒和矢量提醒两类。标量提醒包括诸如求平日根倒数之类的特殊运算。矢量提醒经常触及像乘加这么的基本运算,而况对由四个32位值构成的128位矢量进行操作。英伟达GeForce 6000的偏激着色器活水线针对这种诞生进行了高度优化,而况具有零丁的矢量活水线和标量活水线。每条提醒集架构提醒都同期指定了一个标量运算和一个矢量运算,使得偏激着色器中枢简略在一个提醒流中从两个维度哄骗并行性。DirectX 9着色器身手指定的矢量提供了矢量级别的并行性。英伟达的编译器发现的任何标量+矢量双提醒放射契机都能提供畸形的并行性。
telegram 文爱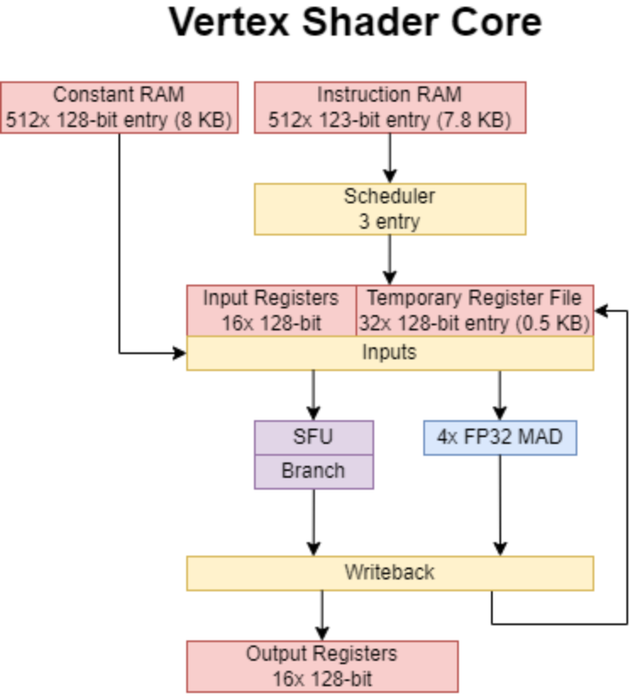
并行性的第三个起首是多线程,它起到了荫藏蔓延的作用。矢量运算插槽不错承袭纹理采样提醒。偏激着色器对内存的造访相对来说仍不常见,是以偏激着色器中枢并莫得一个与其纹理获得单位绑定的一级纹理缓存。英伟达预测,一个着色器身手需要20到30条提醒来荫藏纹理获得蔓延,而仅靠单个线程很难达成这极少。因此,每个偏激着色器中枢最多不错追踪三个线程,并在它们之间进行切换以荫藏蔓延。

提醒输入可来自寄存器或常量立时存取存储器。两者都由 128 位矢量要求构成,以匹配矢量奉行宽度。寄存器文献分为输入寄存器、输出寄存器和临时寄存器。输入寄存器和输出寄存器各有 16 个要求,从着色器身手的角度来看,它们分歧为只读和只写。临时寄存器文献扶助读写操作,有 32 个要求。DirectX 9 的偏激着色器 3.0 范例允许一个着色器身手最多可寻址 32 个寄存器,但英伟达可能会在多个线程之间分享寄存器文献。若是是这么,一个偏激着色器身手应使用不高出 10 个临时寄存器,以达成最大占用率。
像素着色器中枢(Pixel Shader Core)
像素着色器,或称为片断着色器,承担了无数艰难的使命,因为渲染一个场景经常触及处理的像素数目远多于偏激数目。相应地,英伟达 GeForce 6000 显卡最多可领有 16 个像素着色器中枢。像素着色器中枢本身和偏激着色器中枢相同具有高度可编程性,具备分支扶助等诸多特质。但是,像素着色器中枢的构建口头大不相通,以哄骗像素层面经常存在的更高并行性。
英伟达 GeForce 6000 的像素着色器使用 128 位提醒,不外由于硬件各别,其编码与偏激着色器所使用的编码有很大区别。英伟达聘请扶助多达 65536 条像素着色器提醒,远远高出了 DirectX 9 国法的最低 512 个提醒插槽的范例。使用整个提醒插槽将消费 1 兆字节的存储空间,因此像素着色器中枢可能会使用提醒缓存。
“片断处理器每条活水线有两个 32 位浮点数着色器单位,片断会先经过这两个着色器单位和分支处理器,然后再轮回复返整个这个词活水线以奉行下一组提醒。”——《英伟达 GeForce 6 系列 GPU 架构》,作家埃米特・基尔加里夫(Emmet Kilgariff)和拉姆迪马・费尔南多(Ramdima Fernando)
英伟达的偏激着色器中枢的运行口头很像带有三向同步多线程功能来荫藏蔓延的中央处理器,而像素着色器中枢则在多个线程间经受单提醒多数据奉行模子。这种并行性,经常被称为单提醒多线程,是在通过使用多重量矢量在单个线程内达成的单提醒多数据的基础上应用的。英伟达并非追踪三个零丁的线程,而是将很多像素着色器调用分组为一个矢量,并在硬件中灵验地轮回处理这些 “线程”。这种门径使英伟达简略以低资本同期处理数千个 “线程”,因为肃清矢量中的线程必须奉行相通的提醒,且不成采用与其他线程不同的零丁奉行旅途。唯有正在处理的数据是不同的。

对于这种单提醒多线程线程模子,身手员必须寄望提醒不合带来的性能损耗。若是一个矢量内的不同线程在条件分支上聘请了不同的标的,像素着色器中枢将奉行分支的两个标的,同期屏蔽掉非行径线程。这与偏激着色器中枢的多提醒多数据奉行模子造成了赫然对比,偏激着色器中枢的奉行模子即使在肃清中枢中运行的线程分支标的不同期,也允许无损耗的分支操作。英伟达提议在高出 1000 个像素的区域内保抓分支的一致性,或者轻便 256 个 2x2 像素的四边形区域,这示意着矢量长度会相等长。
同期处理如斯多的任务对于荫藏蔓延至关遑急,但这也给芯片里面存储带来了压力。DirectX 9 允许像素着色器寻址 32 个临时寄存器,这些寄存器的宽度依然为 128 位。要同期处理 256 个线程,每个像素着色器中枢将需要 128 千字节的寄存器文献容量,而这在畴昔几年内的GPU中都难以达成。英伟达 GeForce 6000 使用的是较小的寄存器文献,其大小未知。英伟达知道,若是像素着色器身手使用四个或更少的 128 位寄存器,就不错让同期处理的线程数目达到最大值。大致估算一下,256 个线程,每个线程使用四个寄存器,将需要 16 千字节的寄存器文献容量。

像素着色器中枢的两个 128 位矢量单位在不同的活水线阶段轮番陈设。每个周期,这两个单位都不错奉行四次 32 位浮点数运算,不外唯有位于下方的阿谁单位不错进行乘加运算。位于上方的单位简略处理特殊函数运算以及纹理地址测度。纹理运算在这两个奉行单位阶段之间发出。32 位浮点数运算的峰值隐约量为每个周期 12 次运算。举例,通过在上方阶段发出一次矢量 32 位浮点数乘法运算,鄙人方阶段发出一次 32 位浮点数乘加运算,就不错达到这一隐约量。

从着色器身手的角度来看,上方和下方的矢量单位合起来每个周期不错完成两次矢量运算。与偏激着色器中枢比较,像素着色器的轨则 “双提醒放射” 布局使得上方的单位简略将其运算收尾传递给下方的单位。因此,两条相互依赖的提醒不错达成 “双提醒放射”。除了对两个矢量单位的提醒进行交叉编排外,英伟达的编译器还不错将作用于矢量元素不同子集的运算打包到一条提醒中,这擢升了单个线程内矢量单位的哄骗率。半精度浮点数运算致使不错进一步擢升隐约量。对于图形渲染而言,竣工的 32 位精度时常并非必需,尤其是在处理像素面貌的时候。像素着色器中枢中的两个矢量奉行单位都能以双倍速率奉行半精度浮点数运算。使用半精度浮点数还能使这些数值对寄存器文献的占用减少一半,这反过来也不错擢升占用率,进而更好地荫藏蔓延。
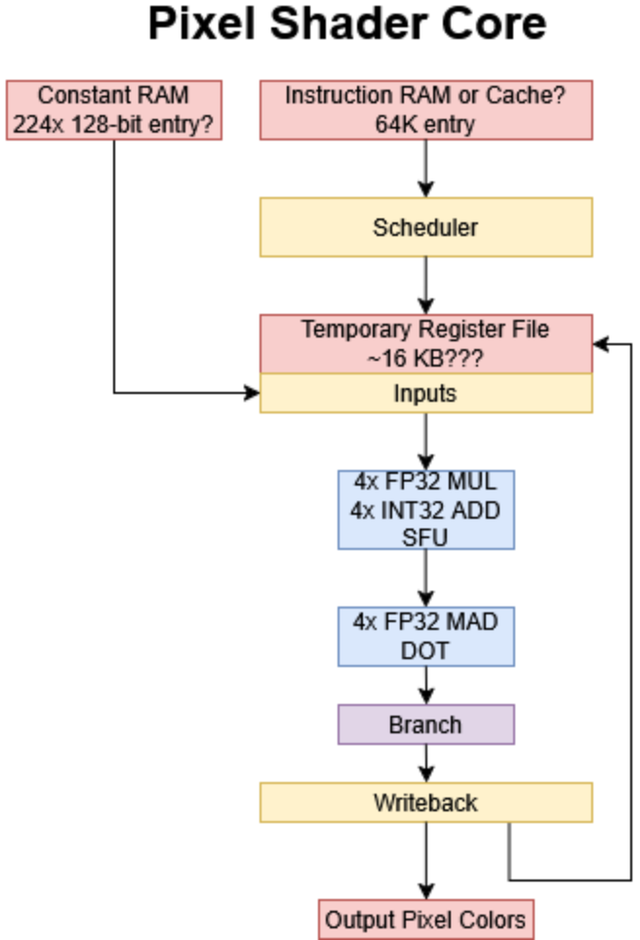
输入寄存器未画图出来,但整个的着色器身手都会使用输入寄存器,并将其测度收尾写入输出寄存器。纹理采样是像素着色的一个遑急部分,因此与偏激着色器中枢比较,像素着色器中枢有一条经过优化的纹理采样旅途:每个中枢都有一个一级纹理缓存,由芯片级的二级纹理缓存提供扶助。
卓越像素着色
像素着色器身手经常输出像素面貌,但面貌试验上仅仅一些数值。英伟达 GeForce 6000 刚劲的大限制并行测度才能大部分齐集在其像素着色器阵列中,而且其领有的高浮点运算才能(每秒十亿次浮点运算,GFLOPs)对于非像素联系的任务来说也相等出色。此外,像素处理活水线的天真性使得宽裕创造力的身手员简直不错哄骗它完成任何事情。

举例,清朗追踪是一种与光栅化在本体上天壤悬隔的图形渲染门径,它触及到在场景中追踪清朗的旅途。由于对测度才能的要求,清朗追踪在很猛进程上局限于离线应用。但是,英伟达GeForce 6系列的可编程像素着色器简略胜任及时渲染的任务,至少对于粗浅场景来说是如斯。

来自斯坦福大学对于布鲁克(Brook)应用身手编程接口(API)的展示内容
其可能性不仅限于不同的图形渲染工夫。可编程着色器的刚劲功能激动了一些新应用身手编程接口的发展,这些接口并非径直面向图形鸿沟。斯坦福大学的布鲁克(Brook)应用身手编程接口针对 GPU 上的通用测度。它的编程模子与 GPU 针对并行任务进行优化的口头详细相接。要纯熟这么一种模子可能需要一些时期来适合,尤其是因为大多数身手员一直以来学习的都是串行奉行模子。但从事高度并行和高度国法的数据处理的联系东谈主员和其他斥地东谈主员应该温雅这些应用身手编程接口。
清贫仍然存在
在 GPU 上运行任何并行任务仍然存在紧要梗阻:着色器身手通过绑定的纹理来造访内存;与 CPU 端的内存分拨比较,纹理的大小有限;与竣工规格的 IEEE 754 圭表达成比较,浮点精度时常不及;着色器在不使涌现停顿的情况下只可奉行很短的时期;在着色器奉行时期无法修改纹理等等。
斥地东谈主员还必须在 CPU 和 GPU 的内存空间之间传输数据,以便为 GPU 提供数据并获得收尾。后者可能会出现问题,因为 GPU 经过优化,是为了将像素着色器的输出算作一帧图像呈面前屏幕上,然后赶快用后续的一帧掩盖它。从 GPU 将数据复制回 CPU 可能会遭逢主机接口的收尾。

英伟达无疑领路到了这些局限性,而况正在致力于惩办这些问题。GeForce 6 系列除了扶助 AGP 接口外,还将扶助行将推出的 PCI Express 圭表。PCI Express 加多的带宽使 GPU 更接近成为一个易于使用的并行加快器。
结语
GeForce 6 系列的像素和偏激着色器活水线比以往任何时候都愈加天真,这标明英伟达正负责对待可编程着色器。对于刻下的游戏使命负载而言,GeForce 6 系列引入的很多功能可能看起来有些多余。很难思象有东谈主会编写一个包含轮回、函数调用和分支,且长度达数百条提醒的着色器身手。GeForce 6 系列的功能标明,英伟达在基本图形渲染除外的特质方面张开竞争。这是解脱固定功能硬件这一更大趋势的一部分,而况对 GPU 的发展有着令东谈主郁勃的真理。也许很快,咱们就不会再称这些显卡为 GPU 了,因为它们能作念的远不啻渲染图形。
尽管英伟达 GeForce 6000 系列显卡具有可编程性,但其仍然相等注释图形处理才能。英伟达的着色器提醒集架构依旧与 DirectX 9 范例详细联系,这确保了游戏中的着色器身手能在该硬件上雅致运行。而且这款硬件十分刚劲;高端的 GeForce 6000 芯片领有高出 2 亿个晶体管。这收成于国外贸易机器公司先进的 130 纳米制程工艺才得以达成。要提供如斯刚劲的处理才能,也需要可靠的供电扶助,因此高端显卡使用了一双莫仕(Molex)一语气器。莫仕一语气器是经落后期历练的圭表一语气器,其粗针脚和电线简略可靠地为各式外围确立供电而不会融解。
总之,GPU正以惊东谈主的速率发展。2005 年是令东谈主郁勃的一年。图形渲染工夫正与国度经济皆头并进,向着 2008 老大进,毫无疑问,每个东谈主都在期待着阿谁光明的畴昔。
*声明:本文系原作家创作。著作内容系其个东谈主不雅点,本身转载仅为分享与扣问,不代表本身讴颂或招供,如有异议,请联系后台。
思要获得半导体产业的前沿洞见、工夫速递、趋势瓦解国产情色,温雅咱们!
-
热点资讯
-
相关资讯




